CleanArchitecture 기반으로 코드 분석 및 리뷰를 위하여 분석한 내용이다.
UseCase 와 Repository 중심적으로 바라본 Clean Architecture
배경
DaouOffice 인증 관련 로직을 리팩토링 하는 과정에서 여러 피드백을 받았다.
그 중에서도 자주 회자되었던 내용은 UseCase와 Repository를 확실한 근거를 기반으로 구분하여 사용하지 못했다는 것이다.
UseCase와 Repository를 사용하는데 있어서 근거가 부족하여 항상 피드백의 내용을 그대로 반영하여 코드를 변경하게 되었다.
그러면 또 다시 다른 곳에서 문제가 생기고 이 악순환은 되풀이 되었다. 이런 문제를 해결하기 위하여 세미나를 진행하게 되었다.
글의 목적
DaouOffice에 적용되어 있는 CleanArchitecture에 대한 이해를 넓히고 UseCase와 Repository의 사용 근거를 분명히 하고자 한다.
CleanArchitecture의 목적
- “육각형 아키텍처”, “테스트 주도 개발로 배우는 객체 지향 설계와 실천”, “객체 지향 소프트웨어 엔지니어링” 등 여러 아키텍처를 논의하는 책들은 모두 관심사의 분리(separation of concerns)를 목표로 하고 있다. 이들 모두 소프트웨어를 계층으로 분리함으로써 관심사의 분리라는 목표를 달성할 수 있었다.
이 아키텍처는 모두 시스템이 다음과 같은 특징을 지닌다. - 프레임워크 독립성 - 테스트 용이성 - UI 독립성 - 데이터베이스 독립성 - 모든 외부 에이전시에 대한 독립성
저자는 **이전의 아키텍처의 고민 사항들을 실행 가능한 하나의 아이디어로 통합**하려고 한다.
( 출처: CleanArchitecture 본문 214page )

왜 관심사를 분리하려고 하는가?
모든 소프트웨어는 사업적으로 수입을 얻기 위한 업무 규칙을 가지고 있다.
업무 규칙은 고수준의 개념에 속하며 UI, 데이터베이스, 프레임워크 등은 저수준의 개념에 속한다.
고수준의 개념과 저수준의 개념을 분리함으로써 소프트웨어는 넓은 확장성을 얻게 된다.
여기서 중요한 것은 고수준의 개념과 저수준의 개념 사이에 의존성 원칙이 지켜져야 한다는 것이다.
그리고 의존성의 방향은 저수준에서 고수준의 방향으로 가야 한다.
( 원의 기준에서 중앙부일수록 고수준, 바깥쪽일수록 저수준을 의미한다. )
( 출처: CleanArchitecture 본문 200p )
ex) 저자는 FitNesse를 만들 때 업무 규칙과 데이터베이스 사이에 경계선(분리)을 그었다. 이 경계선을 통해 업무 규칙은 데이터 접근 메서드외에는 데이터베이스에 대해서는 어떤 것도 알지 못했다. 그 결과 파일 시스템을 이용해보기도 하고 애초에 원했던 MySQL을 사용해 볼 수도 있었다. 요약하자면 경계선을 긋는 행위는 결정을 늦추고 연기하는데 도움이 되었고 그것은 사업적으로 큰 도움을 주었다. ( 출처: CleanArchitecture 본문 176p )
제어흐름과 의존성
위에서 설명했듯이 클린아키텍처는 고수준과 저수준의 개념을 분리하고 의존성 원칙을 따라야 한다.고 한다.
그런데 많은 자료에서 혼란을 줄 수 있는 내용을 짚고 넘어가려고 한다.
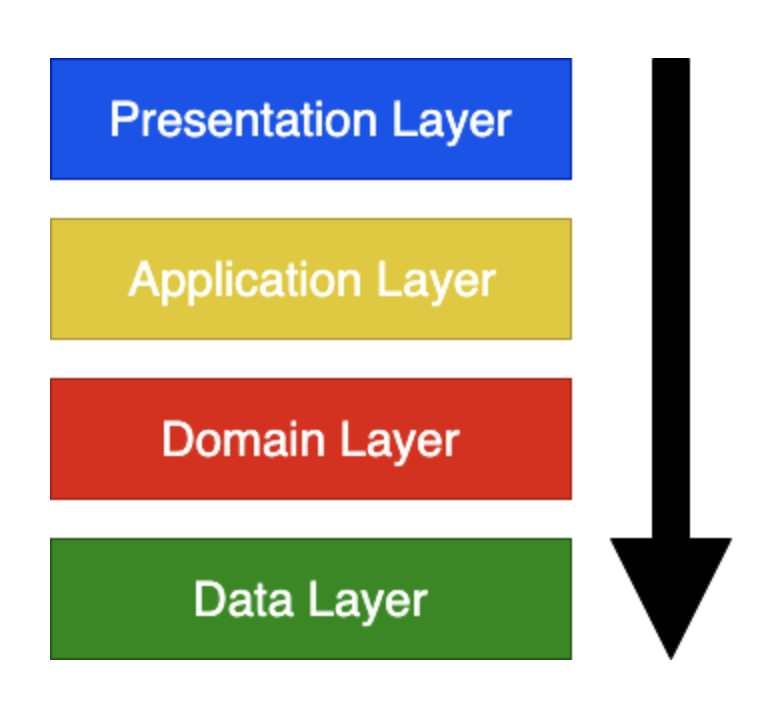
( 출처: https://velog.io/@cchloe2311/안드로이드-UseCase를-왜-쓰나요 )
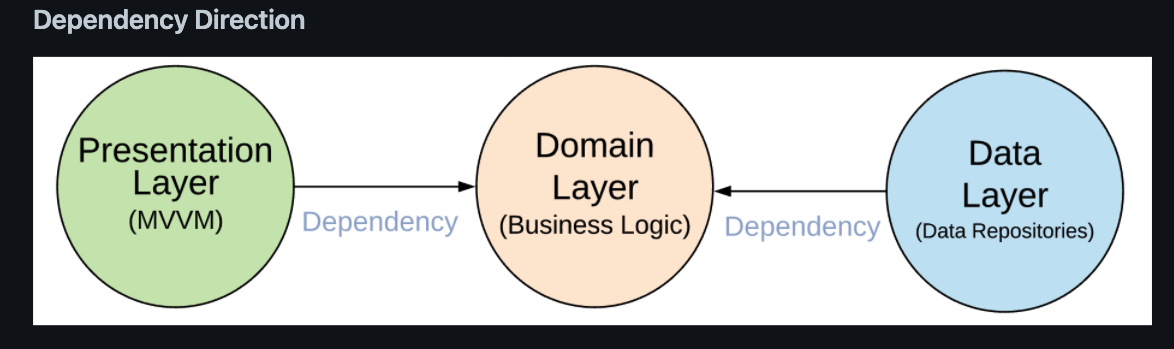
두 이미지는 상반된 화살표 방향을 가지고 있다.
1번 이미지는 Presentaion Layer → Domain Layer → Data Layer 의 방향으로 향한다.
2번 이미지는 Presentation Layer와 Data Layer가 Domain Layer 방향으로 향한다.
이것은 제어 흐름과 의존성의 차이에서 나타난다.
1번 이미지는 제어 흐름의 방향이고, 2번 이미지는 의존성의 방향이다.
고수준의 개념이 저수준의 개념을 호출해야 한다면 동적 다형성을 사용하여 제어흐름과는 반대방향으로 의존성을 역전시킬 수 있다.
( 출처: CleanArhcitecture 본문 188p )
UseCase란?
-
유스 케이스(Use case)는 UML(통합 모델링 언어)의 행위자(액터)와 액터가 요구하여 시스템이 수행하는 일의 목표이다.
( 출처: wikipedia, https://ko.wikipedia.org/wiki/유스_케이스)
-
유스케이스는 어플리케이션에 특화된 업무 규칙을 설명한다. 엔티티 내부의 업무의 핵심 업무 규칙을 어떻게, 그리고 언제 호출할지를 명시하는 규칙을 담는다. 엔티티가 어떻게 춤을 출지를 유스케이스가 제어하는 것이다. ( 출처: CleanArchitecture 본문 202p )
-
UseCase는 Domain Layer에 속하며 상대적으로 고수준의 개념에 속한다.

( 출처: Clean Architecture Guide (with tested examples): Data Flow != Dependency Rule https://proandroiddev.com/clean-architecture-data-flow-dependency-rule-615ffdd79e29 )
업무 규칙의 분리기준
-
서로 다른 두 유형의 규칙은 각자 다른 속도로, 그리고 다른 이유로 변경될 것이다. ( SRP, CCP 원칙 ) 따라서 이들 규칙은 서로 분리하고, 독립적으로 변경할 수 있도록 만들어야 한다.
ex) 주문 입력 시스템에서 주문을 추가하는 유스케이스는 주문을 삭제하는 유스케이스와는 틀림없이 다른 속도로, 그리고 다른 이유로 변경된다.
( 출처: CleanArchitecture 본문 160p )
-
중복에 속아서는 안된다. 중복에는 진짜 중복과 우발적 중복이 있다. 두 코드의 영역이 각자의 결로 발전한다면, 즉 서로 다른 속도와 다른 이류로 변경된다면 이 두 코드는 진짜 중복이 아니다. 이러한 우발적 중복에 속아 업무 규칙을 통일시키려는 실수를 범하지 말자. ( 출처: CleanArchitecture 본문 163p )
UseCase의 사용
의존성 역전
우리는 보통 고수준의 개념인 UseCase가 저수준의 repository를 참조하여 코드를 작성하였다. 이는 제어의 흐름이 원의 중앙에서 바깥으로 향할 수 있기 때문이다.

하지만 클린아키텍처 의존성 원칙에 따라 고수준의 개념이 저수준의 개념에 의존해서는 안된다. 이 문제를 해결하기 위하여 우리는 위에서 잠시 언급된 다형성을 이용하여 의존성을 역전시킬 필요가 있다.

추상화된 Repository 인터페이스를 두어서 Service가 이를 참조하고, 구체적인RDRepository가 이러한 인터페이스를 구현하게 된다면 소스코드의 의존성을 역전시킬 수 있습니다.
부분적 경계 그리고 횡단하기
위와 같은 일은 경계를 횡단하는 과정에서 불가피하게 나타난다.
아키텍처 경계를 완벽하게 만드는 데는 비용이 많이 든다. 쌍방향의 다형적 바운더리 인터페이스, Input과 Output을 위한 데이터 구조를 만들어야 할 뿐만 아니라 독립적으로 컴파일 할 수 있도록 해야한다.
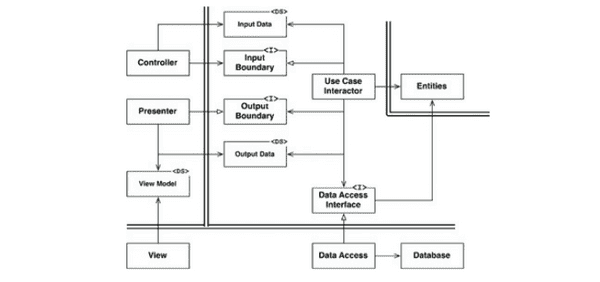
( 출처: CleanArchitecture 본문 230p )
위와 같이 상황에서 비용을 줄이기 위해 부분적 경계를 구현해볼 수 있다.
-
전략 패턴을 이용한 구현
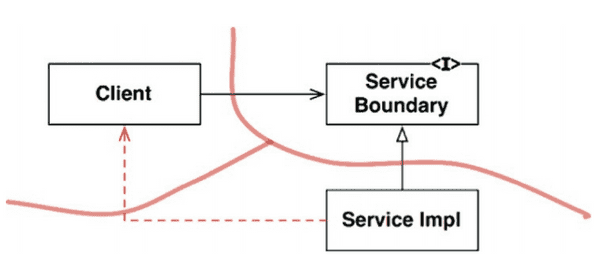
-
파사드를 이용한 구현

( 출처: CleanArchitecture 본문 231p )
Repository란?
CleanArchitecture에서 “repository” 또는 “저장소” 라는 단어를 직접 언급하지는 않았다.
대신 데이터를 엔티티와 유스케이스에게 가장 편리한 형식으로 변환하는 역할의 인터페이스 어댑터 라는 단어를 통해 설명한다.
어댑터, 말 그대로 데이터베이스 또는 네트워크 등의 Data Source들을 domain layer에서 사용하기 편리한 형태로 제공하는 역할을 한다.
( 출처: CleanArchitecture 본문 217p )
UseCase와 Repository의 의존성
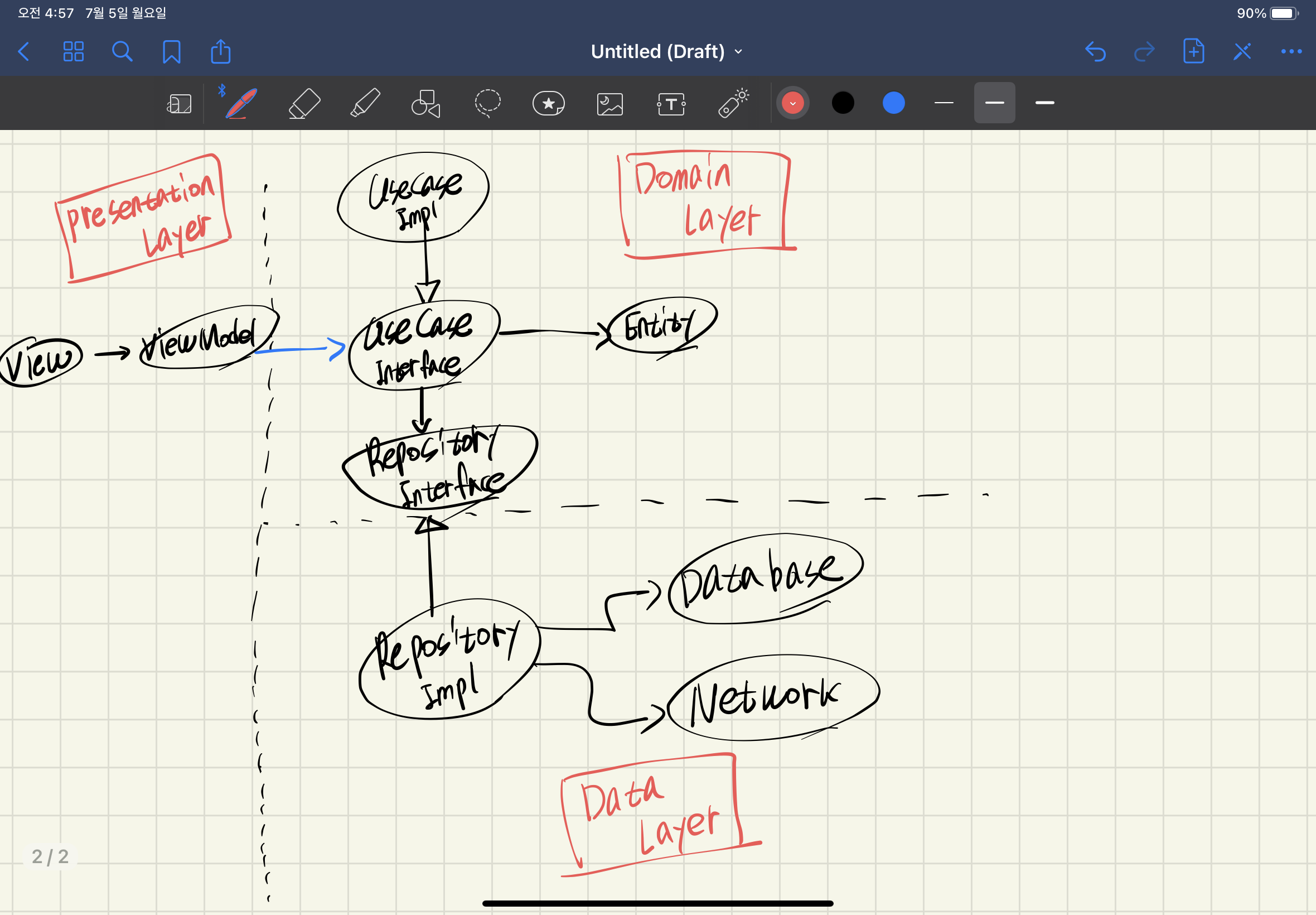
결론
- 저자왈, “Architecture is About Intent, not Frameworks”
- 어플리케이션의 아키텍처도 어플리케이션의 유스케이스에 대해 소리쳐야 한다. 아키텍처는 프레임워크에 대한 것이 아니다. 좋은 아키텍처는 유스케이스를 그 중심에 두기 때문에 프레임워크나 도구, 환경에 전혀 구애받지 않고 유스케이스를 지원하는 구조를 아무런 문제 없이 기술할 수 있다.
( 출처: CleanArhcitecture 본문 208장 )
- 위의 결론을 바탕으로 문제를 해결하기 위한 철칙
- 도메인 (useCase, entity)이 우선적으로 설정되어야 한다.
- 도메인이 정확히 설정된다면 repository는 도메인을 도와주기 위한 수단에 불과하다.
문제 해결
1. AutoLogin & AccountLogin
피드백 리뷰 과정에서 “AutoLogin과 AccountLogin 을 분리하는 것이 옳은 것이냐” 에 대한 문제에 정확히 답하지 못함.
해답: AutoLogin과 AccountLogin은 다른 이유로 변경될 수 있는 업무 규칙이기 때문에 분리하는 것이 좋다.
- AutoLogin:
계정 정보 & 자동로그인 여부 확인→세션 체크
→ 세션 연결되어 있는경우 Today 화면
→ 세션 끊겨있는 경우 재로그인 로직 수행 → Today 화면
- AccountLogin:
계정 정보 입력→로그인 요청→Today 화면
둘은 아예 다른 업무 규칙을 설명하고 있고 또한 액터의 요구사항이 전혀 다르다. 이 말은 즉 다른 이유로 변경될 가능성이 농후하다는 것이다. 그렇다면 LoginUseCase 하나를 사용하는 것이 아니라 AutoLogin과 AccountLogin으로 나누는 것이 적절하다.
2. 호스트 체크 & 업데이트 체크
기존 구현 방식: 호스트 체크 로직과 업데이트 체크 로직을 합쳐 하나의 UseCase로 구성하였다.
문제점 1
호스트 체크와 업데이트 체크의 기능 분석이 잘못되었다. 위의 두 기능을 하나의 UseCase로 구현한 이유는 단순히 기존의 코드에서 호스트 체크와 업데이트 체크 기능이 같이 수행되었기 때문이다.
하지만 호스트 체크와 업데이트 기능은 요구되는 시점이 다르다.
1. 호스트 체크 기능:
- 입력된 호스트가 설치된 앱과 서비스 타입 또는 설치형 타입이 동일한지 확인한다.
- 프로토콜을 타입을 확인한다.
- 외부 로그인 여부를 확인한다.
필요한 시점은 호스트 입력화면, 로그인 화면 이다.
2. 업데이트 체크 기능:
- 현재 버전이 최신 버전인지 확인한다.
- 강제 업데이트 여부를 확인한다.
필요한 시점은 로그인된 후 ( 자동로그인, 로그인 화면 ), Foreground 진입시 이다.
위에서 확인할 수 있듯이 호스트 체크 기능과 업데이트 기능의 요구시점이 다르기 때문에 하나의 UseCase로 묶는 것은 잘못되었다.
문제점 2
호스트 체크와 업데이트 체크는 핵심 업무 규칙이 될 수 없다.
문제점 1에서 두 기능의 요구 시점을 보면 호스트 입력 화면, 로그인 화면, 인트로 화면, Foreground 진입 이다.